Emerging Trends of ETL – Big Data and Beyond
Amidst the analysis of driving voluminous data, and the analytics challenges, there are concerns about whether the conventional process of extract, transform and load (ETL) is applicable.
ETL tools quickly “intrude” across Mobile apps and Web applications as they can access data very efficiently. Eventually, ETL applications will accumulate industry standards and gain power.
Let’s discuss practically something rather new – that offers an approach to easily build sensible, adaptable data models that dynamize your data warehouse: The Data Vault!
Enterprise Data Warehouse (EDW) systems intent to sustain an authentic Business Intelligence (BI) for the data-driven enterprise. Companies must acknowledge critical metrics which are deep-rooted in this significant and dynamic data.
Challenges that wreck ETL with traditional data modelling
Following is a list of top 5 challenges that ETL faces due to traditional data modelling:
- Issue #1: When upstream business flows or when business rules of EDW/BI systems adapt Change.
- Issue #2: Analysis of business data in terms of Volume, Velocity, Variety, Visualization, Veracity and Value (6Vs) – Big Data with technical realities to affirm competitive edge.
- Issue #3: To design, create, deliver, and sustain vigorous, accessible large powerful storage EDW/BI systems for intelligent adoption has become Complex.
- Issue #4: To tailor the data to meet the needs of the business with its core Business Domain value, without failing in giving simple solutions for the definite needs of the business.
- Issue #5: Lack of Flexibility to adopt new unpredicted and unplanned sources with or without the impact of upstream process.
Now it’s time to emerge with much focused, all time solution for all the potential challenges depicted above.
Data Vault is a methodology with Hybrid Data modelling.
As per Dan Linstedt it is detailed as follows:
“A detail oriented, historical tracking and uniquely linked set of normalized tables that support one or more functional areas of business. It is a hybrid approach encompassing the best of breed between 3NF and Star Schemas. The design is flexible, scalable, consistent and adaptable to the needs of the enterprise.”
It’s elegant, easy, and simple to execute. It is established on a set of too many structures, and with auditable rules. By exploiting the Data Vault principles your project will undoubtedly gratify auditability, scalability, and flexibility.
The following stipulated standards will help you to build a Data Vault:
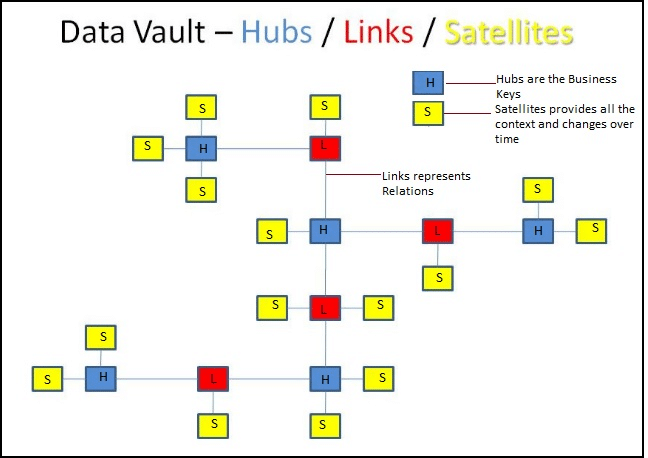
- Step 1: Determine the Business Keys, Hubs
- Step 2: Confirm the relationships between the Business Keys, Links
- Step 3: Specify the description around the Business Keys, Satellites
- Step 4: Connect Standalone factors like Time dimension attributes and code/descriptions for decoding in Data Marts
- Step 5: Integrate for query optimization, append performance tables like Bridge tables and Point-In-Tim (PD) structure model tables.
Building a Data Vault is simple as you go; ultimately it will mutate the conventional methods generally used in Enterprise Integration Architectures. The model is built in a way that it can be efficiently extended whenever required.
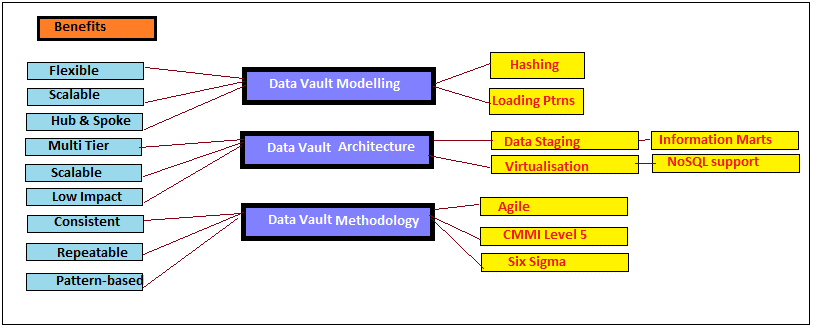
Data Vault Modelling + Architecture + Methodology provides solutions for the challenges depicted above.
“Business Agility is the ability to improve from Continuous Change.”
Let’s see how Data Vault can adapt the “Change”.
With the partying of business keys (as they are static) in Data Vault and the associations between the business keys from their descriptive attributes, Data Vault can address the problem of change in the environment.
Crafting these keys as the structural backbone of a data warehouse, all the associated data can be organized around them. These Hubs (business keys), Links (associations), and SAT (descriptive attributes) yield an extremely adaptable data structure while sustaining an immense degree of data integrity. Specific Links are like synapses (vectors in the opposite direction). They can be created or dropped whenever the business relationships are bound to change automatically by transforming the data model as needed without any impact to the existing data structures.
Let’s see how Data Vault engulfs the ETL challenge of Big Data.
Data Vault blends consistent integration of Big Data technologies along with modelling, methodology, architecture, and outstanding practices. With the adoption of very large voluminous data, data can easily be blended into a Data Vault data model to incorporate adopting products like Hadoop, MongoDB, and various other NoSQL varieties. Eradicating the cleansing specifications of a Star Schema design, the Data Vault triumphs over huge data sets by reducing exhaustion and sustaining correlated insertions which impact the potential of Big Data systems.
Data Vault also decodes the challenge of complexity through Simplification. Let’s see how.
Designing a competent and dynamic Data Vault model can be done instantaneously once you know the core of the 3 table types: Hub, Satellite and Link. Determining the business keys and specifying the Hubs is invariably the perfect thing to kick-off. ‘Hub-Satellites’ simulate source table columns that can change and certainly Links connect them. It is also feasible to have Link-Satellite tables.
Once the Data Vault data model is done, the next uphill task is to build the Data Integration process through ETL (i.e. to populate data into target systems from source systems). So, with the Data Vaults design, you can connect the data-driven enterprise and enable data integration.
ETL, with its simplified development process, decreases the total cost of Open platform. ETL can certainly be used to populate and maintain a robust EDW system built upon a Data Vault model.
This can be achieved through any prominent ETL tools available in the market.
Overcoming the challenge of understanding Business domain using Data Vault:
The Data Vault typically specifies the outlook/values of an Enterprise that analyze and details the business domain and relationships bounded within the vicinity. Accomplishing business rules must ensue before populating a Star Schema. Through Data Vault you can drive the business rules to the downstream, after EDW incorporation/ingestion. Another Data Vault philosophy is that any data is significant, even if it is irrelevant. The theory of the Data Vault is to ingest source data of any type (good, bad).
This data model is designed eminently to resolve and meet the absolute needs of latest and present-day’s EDW/BI systems.
Data Vault is Flexible enough to adopt new unpredicted and unplanned sources without impacting the existing data model.
The Data Vault methodology is based on SEI/CMMI Level 5 processes and practices, and comprises of various components constituting with outstanding features of Six Sigma, Total Quality Management (TQM) and SDLC (Agile). Data Vault projects have short and considerable release cycles usually adopting the repeatable, defined, manageable, consistent and optimized projects expected at CMMI Level 5. While adding new data sources, business keys which are alike and new Hubs-Satellites-Links can be added and then can be linked to the existing Data Vault structures without any impact with underlying model.
Testing a Data Vault – ETL/Data Warehouse pursuit
Unlike in non-Data Vault ETL programs, general testing strategy best suits for any Data Vault adopted programs. However, by using raw Data Vault loads we can moderate transformations to a minimum level in the entire ETL process through “Permissible Load Errors”.
ETL/Data Warehouse Testing should emphasize on:
- Data quality of Source Systems
- Data Integration
- Performance/Scalability/Upgrade issues of BI Reports
Following are the prominent 5 proposals to execute tests for a Data Vault – ETL/DWH project to adhere the above baseline pointers:
- Design a small – static test database derived from the actual data to run the tests quickly and expected results can be identified in the earlier stage.
- Early execution of system testing to ensure the connecting boxes in ETLs interface.
- Using Test Automation tools to:
- Set up the test environment
- Restore a Virtual environment
- Update static data to validate complex data validations
- Execute the ETLs, capture logs and validate Bad/Rejected/Valid data flows
- Engage Business users while creating and deriving the real data to a small test database to ensure the data profiling and data quality.
- Simulate the test environment as is of the Production environment to cut down the cost issues.
To summarize – exploiting various innovative methodologies to visualize the business trends coupled with substantial evidence will do wonders in ETL-Big Data engagements.
Although it is important to discuss on the ETL trends to cop-up the Challenges, it is not enough to stop here. We need to extend and reflect upon how we can develop automation solutions to create Test Data for any ETL requirement using Component Libraries, RowGen (tool).
Cigniti technologies has helped many clients with ETL/Data warehousing testing that produced effective results of quick test cycles and achieved no defect leak to production and significantly met the production go timelines. For any of your ETL/Data Warehousing Testing requirements, Cigniti’s testing experts are available to help you out with your projects.



Leave a Reply