Independent & Fail- Safe Performance Testing is an absolute must for the success of distributed and large scale e-commerce business
The positive and negative impact of Flipkart’s much publicized Big Billion Sale is a classing example of the growing activity in e-commerce. Other reported inconsistencies in the ‘100 million dollar worth sales in 10 hours’ aside, the server downtime was a major source of disappointment for the users who deserved a fair access to the purchase options on the given day.
In a way, downtime is good news for any e-commerce company. It indicates tremendous success in engaging the customers and other stakeholders including vendors, back end IT teams and marketing units. This means the business is heading in the right direction. Only the performance of the IT systems has to be constantly reinforced to match the ‘difficult to predict’ user activity. Fail Safe Performance Testing has become a must for any business environment which thrives on heavy volume transactions 24/7 or during peak seasons.
It is evident that the demand for highly scalable and dependable system is increasing exponentially for IT driven verticals especially e-retail, e-Learning, healthcare etc. In addition, customers are getting less tolerant and excessively vocal on social networks by sharing poor buying experience with screenshots.
When it comes to e-commerce, performance testing assumes multiple dimensions. Performance testing of such a complex system should be done in a layered approach that is both manageable and delivers comprehensive coverage. Big distributed systems can’t be fully tested on UAT environment. There are several levels of testing stretching over a range of speeds, resources, and fidelity to a production system.
For example, a typical large system might consist of thousands of various servers, front-end Web applications, REST API servers, internal services, caching systems, and various databases. Such a system might processes several terabytes of data every day and its storage is measured in petabytes. It is constantly hit by countless clients and users. It is difficult to replicate all this on a UAT environment.
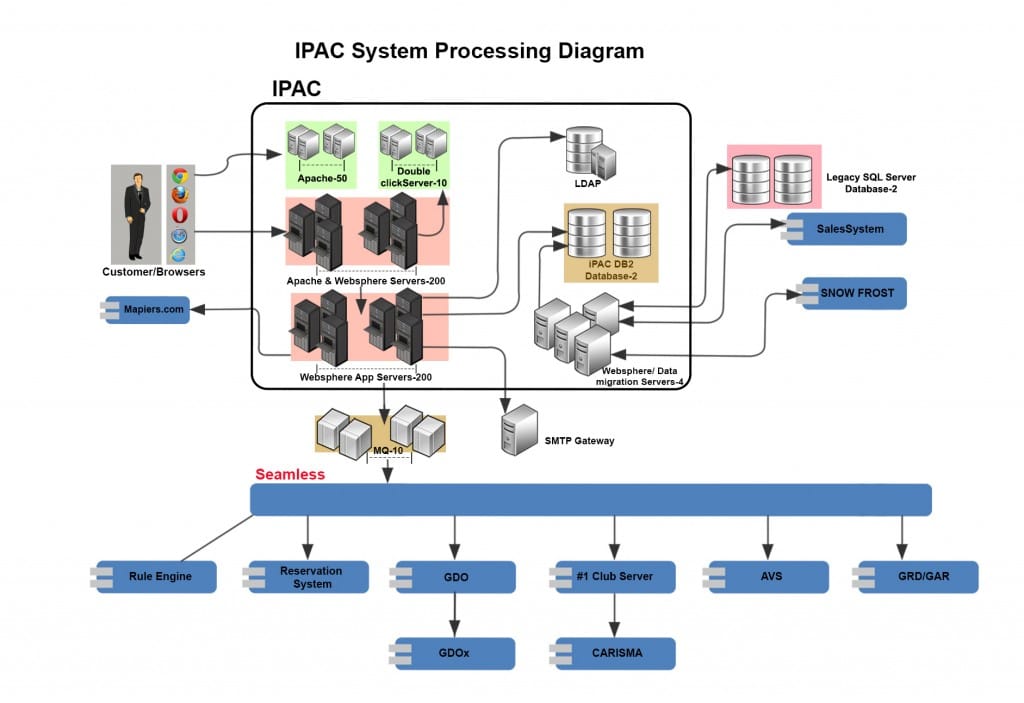
Testing of large scale distributed systems is hard and there is much to test beyond traditional testing methods. Performance testing, load testing, and error testing must all be undertaken with realistic usage patterns and extreme loads.
Traditionally performance testing approach usually follows Identification of Key Scenarios, Setting up the Load Environment, Designing the Scripts, Generating load, Monitoring and at last Analysis and Reporting. It works for most of the system but it is completely a different ball game when conducting performance testing of large scale distributed system.
Business leaders and technology stakeholders need to look at performance from a fresh perspective.
The following table describes some of the characteristics of the common test scenarios associated with large scale distributed systems:
| Key Characteristics | |
| High Volume | » Terabyte of transactional records in database » Network throughput in gigabits per second |
| High Transactions | » Millions of transactions per second from end users » Millions of transactions in database due to few triggers (e.g. large report generation due to batch processing) |
| High Concurrency | » Huge user base accessing simultaneously (e.g. Facebook) |
| Geographically Distributed | » Traffic from all over the world |
| High availability | » Huge revenue loss and complaining customers due to unavailability |
| Huge Data Analytics | » Big data, data warehousing |
The following table describes performance testing solutions to address the business problems associated with a large scale distributed system:
| Key Challenges | Proposed Solution |
| High cost for test environment setup | » Production or staging environment » Scaled down environment |
| High cost for load generation environment | » Cloud based load generation tool |
| High license cost for tools and utilities | » Open source load generation / monitoring tools » Use pay per service if number of runs are less |
| Production like environment configuration | » Use CI tool like Jenkins for automatic build and deployment |
| Configuration consistency for large number of nodes | » Automatic validation of configurations before and after the execution » Take restore point and roll it back after the performance run |
| Population of high volume of test data | » Copy production data and mask it » Alteration of DB volumes » Use tool like database generator, dbmonster » Use historic data |
| Simulation of realistic load | » Identify key scenarios and usage patterns from log files, market research, BA etc. » Generate load from different geographies » Baseline response with CDN and without CDN |
| Penetrating the system complexity, touching all system nodes and database tables | » Understand system architecture » Manually walkthrough the scenarios and watch traffic on different nodes and database tables » Detail analysis of application logs » Understand load balancer strategy |
| Identification and testing of failover scenario | » Test the failover scenario separately during load condition |
| Third party interactions | » Simulate using stubs |
| Monitoring of large number of disparate systems | » Use diagnostic tools like AppDynamics, DynaTrace, HP Diagnostic, Glassbox |
| Result collation and analysis | » Automatic result collection and collation » Collection of built-in anti patterns for quick analysis » Knowledge base on historical failures or bottlenecks |
Conclusion
For an e-commerce company, the user can be any computer literate individual with access to internet. This assumption makes it very difficult to predict user activity because the scenarios that generate peak traffic are susceptible to changing combinations of the demand of a product, the pricing, the launch, availability and UX.
To stay resilient, a fail-safe performance testing consolidates the scenarios into predictable, manageable and contingent performance support strategies that can be implemented to match the traffic with optimized utilization of systems and resources.




Leave a Reply