7 Steps to Execute Chaos Engineering
We’ve all heard about the significant WhatsApp breakdowns recently, during which the app was unavailable to the public for an hour. However, from a technical standpoint, WhatsApp returned in less than an hour. What would have enabled the engineers at WhatsApp to restore the services quickly?
What is Chaos Engineering?
Technically speaking, the team experienced an extremely stressful production failure because of this. Indeed, significant corporations like Netflix, Facebook, Google, and others use a technique called Chaos Engineering.
The purpose of chaos engineering is to learn how our system will behave during catastrophic failures in production and how resilient our system is, allowing us to optimize and fix the issues.
Chaos engineering involves testing a system to increase confidence in its ability to endure turbulence during production. You can use chaos engineering to compare what you expected to happen to what happened. To understand how to create more resilient systems, we need to “break things on purpose.”
When we were little, we used to pick up wooden sticks off the ground and bend them to split them in half. The point at which the stick breaks interests us most, though. The point truly represents the stick’s ability to bear stress and pressure.
- Start with a hypothesis – Measuring the strength of a wooden stick
- Measure baseline behavior – Typical power of the stick
- Inject a fault or failure – Break / Hammer the stick
- Monitor the resulting behavior – Observing the point when the stick breaks
Chaos engineering is to observe, track, react to, and enhance the reliability of our systems in challenging conditions.
7 Steps to Execute Chaos Engineering
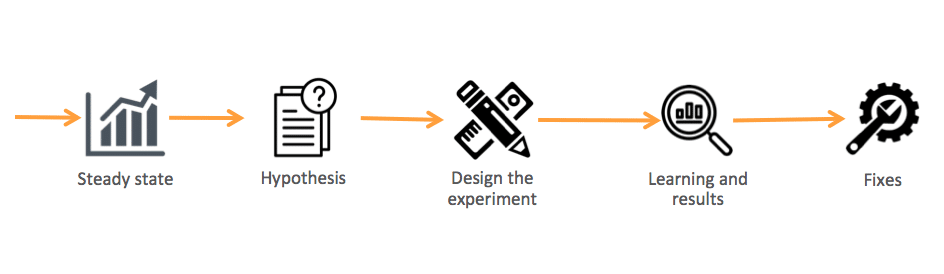
System Architecture
Before running your chaos experiments, thoroughly understand your system’s architecture. Discuss the application architecture in a working session with your developers, architects, and SREs, and learn about the upstream/downstream components, dependencies, timeframe, deployment schedule, and other factors. This will help you understand where exactly your system could fail.
Step 3. Write a Hypothesis
Start writing a list of hypotheses, such as what might go wrong. Example: If a site has numerous nodes and one goes down, the load balancer must rapidly reroute traffic to the remaining healthy nodes. Additional instances of this kind include failing hard drives, broken network connections, potential production interruptions, etc. The main point is that there is no right or wrong when listing the hypotheses. It is an iterative process. Making our belief TRUE or FALSE is NOT our goal. Each theory will allow us to learn more about our system.
Step 4. Minimize the Bang
Always get going slowly. By reducing the blast radius, chaotic experiments can be conducted with less impact on the users. Example: Delete the build deployment flow in Jenkins and validate the resiliency. Even if you are deleting a deployment flow, make sure GitOps is active so that the GitOps flow will create the build deployment automatically. Another illustration would be to shut down a zone of the server rather than the entire region or to turn down 50% of the cluster’s active nodes. You can progressively extend the blast radius once the chaos process has evolved and your crew is at ease.
Step 5. Plan for a Play Date
Always think ahead and have a Plan B handy. Set up a unified communication channel in Teams (or your company’s communication platform) to post updates periodically and notify all relevant stakeholders at least one week in advance. It is advisable to assemble your own Avengers team of developers, testers, DevOps, SREs, and others to support you when you ignite your first experiment.
Step 6. Run your First Experiment
Running the first chaos experiment is like riding a thrilling roller coaster. Make sure you can stop the experiment and reverse the infrastructure with the aid of your Avengers squad in case things go wrong. To conduct an experiment, your system must be intentionally broken so that some infrastructure components are unavailable. Examples include shutting down working processes, deleting database tables, stopping access to internal-external services, and terminating cluster machines.
Although these experiments are challenging, you will be astonished by how much you can learn from Chaos no matter what you try. Watch your Observability dashboard throughout the experiment to keep track of important metrics like response time, disc usage, pass/fail transactions, health checks, etc. Nobody is flawless. It’s okay if your initial experiment doesn’t go as planned. Post an update as soon as possible, notifying all parties involved.
Step 7. Analyze & Brainstorm the Experiment Results
Once the experiment is complete, record all your observations in a spreadsheet, analyze them, and define your hypothesis verdict. Again, there is only learning and no PASS or FAIL. Schedule a meeting with the respective stakeholders, including your Avengers team, to discuss your verdict. This will help the team understand the verdicts and fix the issues you discovered. You can repeat the experiments after addressing the problems.
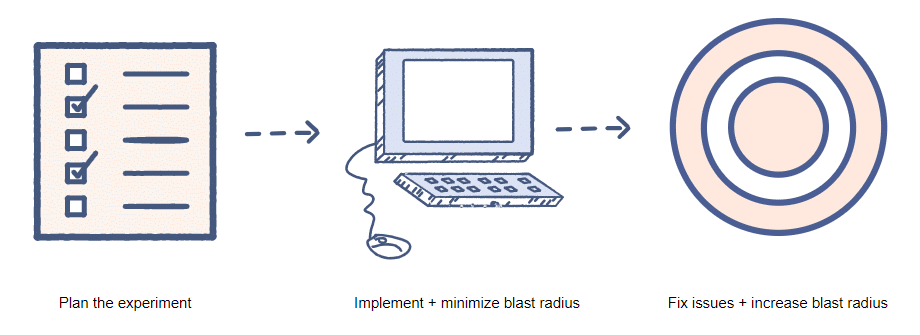
If you discover the system is durable, consider enlarging the explosion radius and repeating the experiments.
Conclusion
Chaos engineering aims to experience disastrous circumstances. Although it may seem challenging and requires a lot of imagination, the extra work is unquestionably worthwhile. You must inject failures into your system to make some infrastructure components unavailable. Later, you can mimic situations like high latency caused by slow networks that can upset the steady state.
Enterprises building distributed systems must exercise Chaos engineering as a resilience strategy. Running Chaos tests continuously is one of several things you can do to improve the resiliency of your applications and infrastructure.
Schedule a discussion with our Chaos Engineering and Testing experts to learn more about the steps in commencing chaos engineering.
Also, join us for a Fireside Chat on October 12th, 2023, where Northern Trust and Gremlin experts will accompany us to discuss the art of Building Resilient Digital Systems Through Chaos Engineering.
Embrace orchestrated chaos, foster resilience, and be part of our insightful Chaos Engineering Fireside Chat dialogue.




Leave a Reply