A Practical Guide to Chaos Engineering
Modern systems are built on a large scale and operated in a distributed manner. With scale comes complexity, and there are so many ways these large-scale distributed systems can fail. Modern systems built on cloud technologies and microservices architecture have a lot of dependencies on the internet, infrastructure, and services that you do not have control over. Cloud infrastructure can fail for many reasons.
|
|
|
|
|
(low memory, high CPU, low bandwidth etc) |
We cannot control or avoid failures in distributed systems. However, we can control the impact radius of the failure and optimize the time to recover and restore the systems. This can be achieved only by exercising as many failures as possible in the test lab, thus achieving confidence in the system’s resilience.
Why Chaos Engineering?
Chaos Engineering is the discipline of experimenting with distributed systems to build confidence in the system’s capability to withstand turbulent conditions in production. Chaos Testing is the deliberate injection of faults or failures into your infrastructure in a controlled manner to test the system’s ability to respond during a failure. This is an effective method to practice, prepare, and prevent or minimize downtime and outages before they occur.
Chaos testing is one of the effective ways to validate a system’s resilience by running failure experiments or fault injections.
What is an Experiment?
An experiment is a planned fault injection in a controlled manner. Experiments vary based on the architecture of the systems under test. However, in a distributed system and microservices architecture deployed on the cloud, below are the most common fault injections that must be exercised.
- Shutdown the compute engines randomly in an availability zone (or data center)
- Outage of an entire region or availability zone.
- Resource exhaustion: High CPU, Low Memory, Heavy Disk Usage
- Data Service Failure – Partially deleting a stream of records/messages across multiple instances to recreate a database-dependent issue.
- Network – Inject latency between services for a select percentage of traffic over a predetermined period.
- Code insertion: Adding instructions to the target program and allowing fault injection to occur prior to certain instructions.
Principles of Chaos Testing

- Define the system’s normal behavior: The steady state can be defined as some measurable output like overall throughput, error rates, or the latency of a system that indicates normal behavior. The system’s normal behavior is believed to be acceptable behavior and unexpected behavior. The normal state of the system should be considered the steady state.
- Hypothesize about the steady state: The hypothesis defined here will be believed to be the expected output of the experiment. The hypothesis of the experiments should be in line with the objective of Chaos engineering: “the events injected into the system will not result in a change from the steady state of the target system.”
- Design and run experiments: Identify all the possible failure scenarios in the infrastructure, design failure experiments and run them in a controlled manner, and ensure there is a backout plan for every failure experiment. If a back-out plan is unknown, identify the path to systems recovery and record the procedures during the recovery.
- Analyse Test Results: Verify if the hypothesis was correct or if there was a change to the system’s expected steady-state behavior. Identity, whether there was any impact on the service continuity user experience, and whether the service is resilient to the failures injected.
Test tools comparison
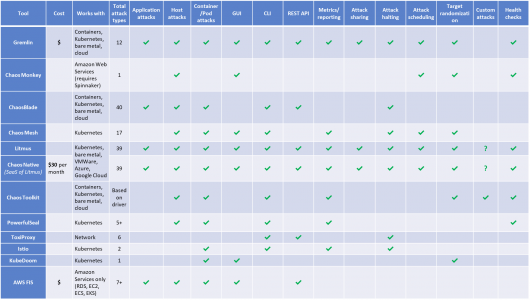
Best Practises
Smaller blast radius: Begin with small experiments to know the unknowns and learn about them. Scale-out the experiments only when we gain confidence. Start with a single compute engine, a container, or a microservice to reduce the potential side effects.
Test tool selection: Perform a study of the test tools available. Compare the available features and the time and effort required to build your tools. We recommend not picking tools that perform random experiments as it would become difficult to measure the outcome. Use the test tools that perform thoughtful, planned, controlled, safe, and secure experiments.
Exercise first in the Lower environment: get confidence in the tests, start with staging or development environment. Once the tests in these environments are complete, move up to production.
Roll Back & Abort planning: ensure effective planning is exercised to abort any experiment immediately and revert the system or service back to its normal state. If an experiment causes a severe outage, track it carefully and do an analysis to avoid it happening again. If these plans are void or cannot be run, exercise effective root cause analysis to learn further about the outage.
Path to achieve maturity of Chaos Testing:
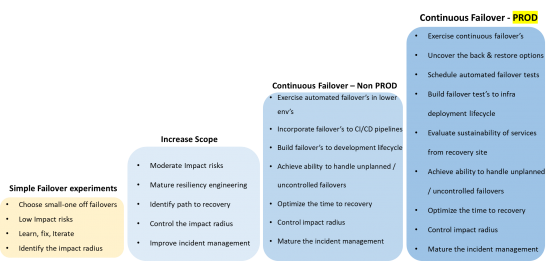
Conclusion
No system is safe from failure or outage. Cloud infrastructure platforms cannot be over-trusted. Every major Cloud infra reported at least one outage in each quarter. We cannot control the failures or outages. You can only control the impact on your customers, employees, partners, and reputation by exercising failures as often as possible in the test lab, thus identifying the path to your systems’ recovery.
Enterprises building distributed systems must exercise Chaos engineering as part of their resilience strategy. Running Chaos tests in a continuous manner is one of several things that you can do to improve the resiliency of your applications and infrastructure.
Cigniti has built a dedicated Performance Testing CoE that provides solutions around performance testing & engineering for our global clients. We focus on performing in-depth analysis at the component level, dynamic profiling, capacity evaluation, testing, and reporting to help isolate bottlenecks and provide appropriate recommendations.
Schedule a discussion with our Chaos Engineering and Testing experts to learn more about Chaos Engineering and testing tools for cloud deployment.
Join us for a Fireside Chat on October 12th, 2023, where we’ll be accompanied by Northern Trust and Gremlin to discuss the art of Building Resilient Digital Systems Through Chaos Engineering. Embrace orchestrated chaos, foster resilience, and be part of our insightful Chaos Engineering Fireside Chat dialogue.




Leave a Reply